Harbor multi datacenter with replicated artifacts
At Veepee, where i’m working as a lead SRE in 2023, we started to work on our next generation Artifact registry for Docker (and helm).
Currently we are using Artifactory as a pulled based registry (with upstream remotes caching) and as a push based from our CI/CD pipelines. This setup is only a single datacenter, because Artifactory licenses are limiting us in terms of deployment, and Artifactory Private Distributed Network (PDN) is very cool, but too expensive for us.
In terms of hosting, we are using multiple datacenters in multiple countries, and it’s clearly suboptimal to download artifacts from a single one, in terms of latency and bandwidth usage, but also it’s a SPOF. Whereas our housting model is very strong in terms of resiliency for a single datacenter, we’d like to improve situation by having a local registry in each datacenter, and replicate artifacts between them.
Here comes Harbor, it’s a CNCF project, and it’s free and it’s Kubernetes native, but also have a docker-compose deployment which is a requirement for a DRP need we have.
Harbor is composed of multiple components:
- core: harbor API
- portal: harbor UI
- registry: docker registry
- chartmuseum: helm registry (will be deprecated in favor of OCI registry)
- notary: signature registry
- trivy: vulnerability scanner
Each part can be enabled or disabled. On our primary datacenters, we will enable all of them, but on DRP datacenter, we will only enable the registry, and the portal to be able to browse the artifacts.
Architecture
Here is the deployment model we choose depending on datacenter type:
- Primary datacenter: All services, backed by S3 storage on Ceph, and Postgresql with Patroni (2 nodes)
- DRP datacenter: Only registry and portal, backed by local storage, and Postgresql with Patroni (single node)
Here is the global architecture scheme:
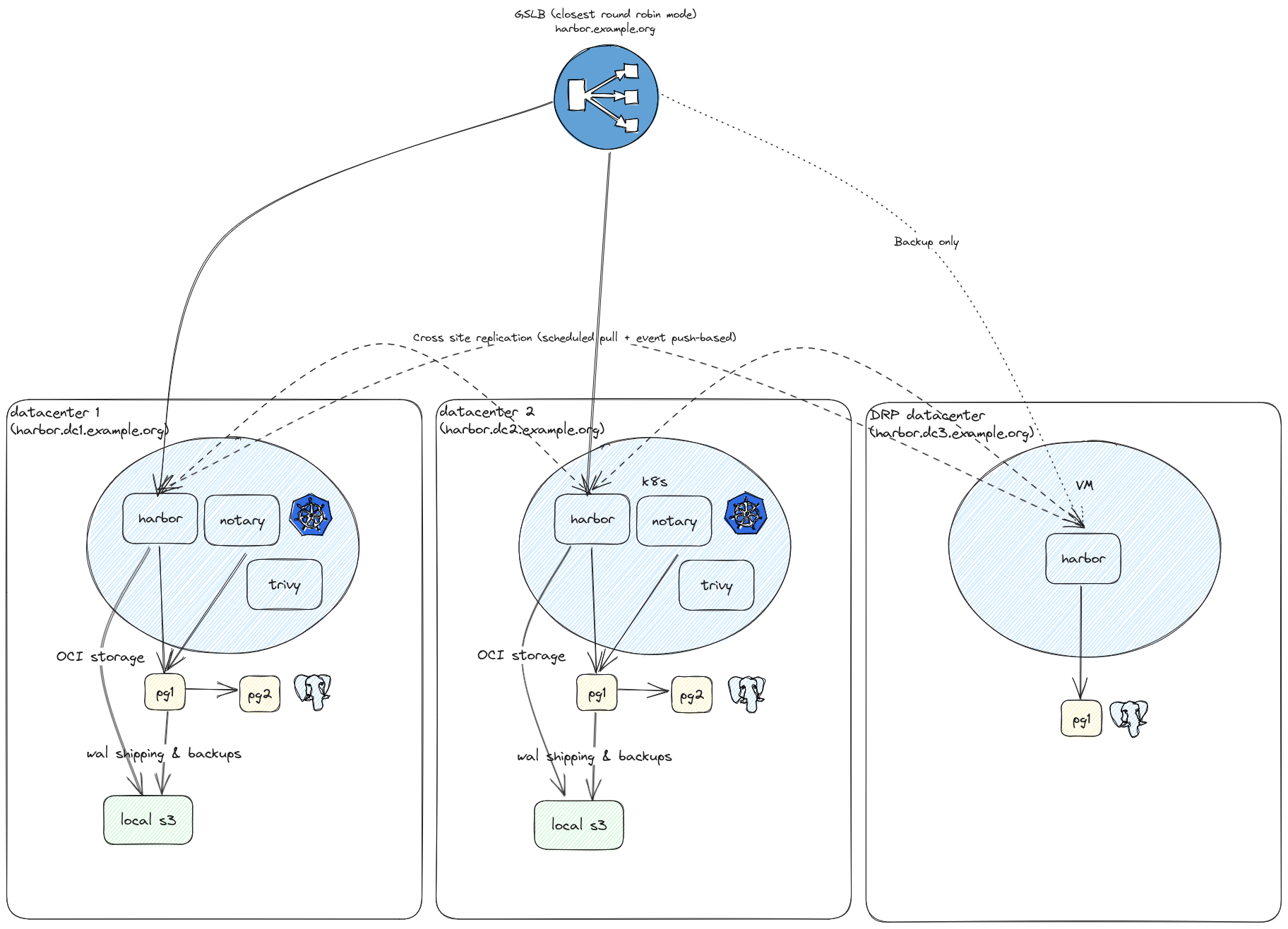
Deployment
On primary datacenters we use official helm chart but added HorizontalPodAutoscaler on core, registry and trivy, to support higher load, on our thousand of users and millions of artifacts.
On secondary datacenters we used the docker-compose officially supported stack.
Each harbor instance run with its own URL in harbor.<datacenter>.example.org.
Then we configure our GSLB to have a single URL for all datacenters, using harbor.example.org and
configure our primary datacenters as active and DRP datacenters as backup. We choose twrr algorithm
which means the GSLB we use will select closest working datacenter. I won’t detail GSLB configuration
as it’s a internal one backed by PowerDNS, but you can achieve the same
on any public cloud provider.
Configuration
Now we have vanilla harbor standalone on their datacenters, it’s time to configure them.
We use vault to store secrets and harbor official terraform provider.
terraform {
backend "s3" {}
required_providers {
harbor = {
source = "goharbor/harbor"
version = "3.9.4"
}
}
}
data "vault_generic_secret" "harbor" {
path = "secret/<amazing vault backed harbor secret>"
}
Then let’s configure some variables, configure harbor provider and the OIDC configuration for our end users (we use keycloak as our OIDC provider).
variable "datacenter" {
description = "Datacenter name"
}
variable "oidc_endpoint" {
description = "OIDC endpoint"
type = string
}
variable "multidc_replicated_repository" {
type = map(any)
default = {}
}
variable "harbor_url" {
description = "Harbor URL"
type = string
}
variable "harbor_remotes" {
description = "harbor remote instances"
type = map(string)
}
provider "harbor" {
url = var.harbor_url
username = data.vault_generic_secret.harbor.data["admin-user"]
password = data.vault_generic_secret.harbor.data["admin-password"]
}
resource "harbor_config_auth" "keycloak" {
auth_mode = "oidc_auth"
oidc_name = "keycloak"
oidc_endpoint = var.oidc_endpoint
oidc_client_id = data.vault_generic_secret.harbor.data["oidc-client-id"]
oidc_client_secret = data.vault_generic_secret.harbor.data["oidc-client-secret"]
oidc_scope = "openid"
oidc_verify_cert = true
oidc_auto_onboard = true
oidc_user_claim = "preferred_username"
oidc_groups_claim = "roles" // doesn't seems to work
oidc_admin_group = "sre"
}
Cross DC replication
Now our harbor is globally configured, we want to have some local repositories replicated on all datacenters.
Pull based mode is intesting but is scheduled. Which means if you push an artifact on a datacenter, it won’t be available immediately on other datacenters, depending on the schedule set. It can be anoying if you are pushing artifact from one datacenter and deploying it on another one.
The solution is to combine both, in order to ensure repo is synced, and recent artifacts are published everwhere. We choose here to pull replicate every 15 min the whole repository.
Here we create a simple map of repositories, prefixed by multi-dc in order to identify it directly in the UI.
Each repository has a default quota of 10GB and a dedicated robot account with pull and push rights. We also put a retention policy to prevent infinite growth. Here it will tag if it’s younger than 180 days or if it’s one of the 10 most recent.
locals {
replicated_registries = merge([
for krepo, vrepo in var.multidc_replicated_repository : {
for k, v in var.harbor_remotes :
k => {
"name" : krepo,
"endpoint_url" : v,
"description" : "${krepo} ${k} remote",
} if k != var.datacenter
}]...)
}
resource "harbor_registry" "multi-dc-replicated" {
for_each = local.replicated_registries
provider_name = try(each.value.provider, "harbor")
name = "multi-dc-${each.value.name}-${each.key}"
endpoint_url = each.value.endpoint_url
description = each.value.description
access_id = "robot$multi-dc-${each.value.name}+${harbor_robot_account.multi-dc-replication-robot[each.value.name].name}"
access_secret = data.vault_generic_secret.harbor.data["robot-password/replication/${each.value.name}"]
}
resource "harbor_project" "multi-dc-replicated" {
for_each = var.multidc_replicated_repository
name = "multi-dc-${each.key}"
public = false
storage_quota = try(each.value.storage_quota, 10)
}
resource "harbor_retention_policy" "multi-dc-replicated" {
for_each = var.multidc_replicated_repository
scope = harbor_project.multi-dc-replicated[each.key].id
schedule = "Daily"
rule {
n_days_since_last_pull = 180
repo_matching = "**"
tag_matching = "**"
}
rule {
most_recently_pulled = 10
repo_matching = "**"
tag_matching = "**"
}
rule {
n_days_since_last_push = 180
repo_matching = "**"
tag_matching = "**"
}
}
// This robot account is to give to end users for read-only
resource "harbor_robot_account" "multi-dc-readonly-robot" {
for_each = var.multidc_replicated_repository
name = "readonly"
description = "Multi DC replication user for ${each.key} repository (configured with Terraform)"
level = "project"
secret = data.vault_generic_secret.harbor.data["robot-password/readonly/${each.key}"]
permissions {
access {
action = "pull"
resource = "repository"
}
kind = "project"
namespace = harbor_project.multi-dc-replicated[each.key].name
}
}
// This robot account is to give to end users for read-write
resource "harbor_robot_account" "multi-dc-readwrite-robot" {
for_each = var.multidc_replicated_repository
name = "readwrite"
description = "Multi DC replication user for ${each.key} repository (configured with Terraform)"
level = "project"
secret = data.vault_generic_secret.harbor.data["robot-password/readwrite/${each.key}"]
permissions {
access {
action = "pull"
resource = "repository"
}
access {
action = "push"
resource = "repository"
}
kind = "project"
namespace = harbor_project.multi-dc-replicated[each.key].name
}
}
// This robot account is to replicate images between registries
resource "harbor_robot_account" "multi-dc-replication-robot" {
for_each = var.multidc_replicated_repository
name = "sync"
description = "Multi DC replication user for ${each.key} repository (configured with Terraform)"
level = "project"
secret = data.vault_generic_secret.harbor.data["robot-password/replication/${each.key}"]
permissions {
// See https://github.com/goharbor/harbor/wiki/How-to-do-replication-with-Robot-Account
access {
action = "pull"
resource = "repository"
}
access {
action = "push"
resource = "repository"
}
access {
action = "list"
resource = "repository"
}
access {
action = "list"
resource = "artifact"
}
kind = "project"
namespace = harbor_project.multi-dc-replicated[each.key].name
}
}
resource "harbor_replication" "multi-dc-replication-pull" {
for_each = local.replicated_registries
name = "multi-dc-${each.value.name} from ${each.key}"
action = "pull"
registry_id = harbor_registry.multi-dc-replicated[each.key].registry_id
schedule = "0 0/15 * * * *"
dest_namespace = "multi-dc-${each.value.name}"
dest_namespace_replace = -1
filters {
name = "**"
}
filters {
tag = "**"
}
}
resource "harbor_replication" "multi-dc-replication-push" {
for_each = local.replicated_registries
name = "multi-dc-${each.value.name} to ${each.key}"
action = "push"
registry_id = harbor_registry.multi-dc-replicated[each.key].registry_id
schedule = "event_based"
dest_namespace = "multi-dc-${each.value.name}"
dest_namespace_replace = -1
filters {
name = "**"
}
filters {
tag = "**"
}
}
Now in tfvars we can create our multidc repositories on each instance easily:
multidc_replicated_repository = {
"repo1" = {}
"repo2" = {}
}
Cache some public repositories
Now we have private registries, it can be desirable to cache public images internally in order to prevent downloading them from the internet each time we need them.
The following code declare remote registries prefixed with cache-, a 1TB quota and a 30 days since last pull
retention policy.
variable "docker_upstream_cached_registries" {
type = map(any)
}
resource "harbor_registry" "docker" {
for_each = var.docker_upstream_cached_registries
provider_name = try(each.value.provider, "docker-registry")
name = each.key
endpoint_url = each.value.endpoint_url
description = try(each.value.description, null)
access_id = try(local.cache_registry_credentials[each.key].username, null)
access_secret = try(local.cache_registry_credentials[each.key].password, null)
}
resource "harbor_project" "public-cache" {
for_each = var.docker_upstream_cached_registries
name = "cache-${each.key}"
public = false
storage_quota = try(each.value.storage_quota, 1024)
registry_id = harbor_registry.docker[each.key].registry_id
}
resource "harbor_retention_policy" "public-cache" {
for_each = var.docker_upstream_cached_registries
scope = harbor_project.public-cache[each.key].id
schedule = "Daily"
rule {
n_days_since_last_pull = 30
repo_matching = "**"
tag_matching = "**"
}
rule {
n_days_since_last_push = 30
repo_matching = "**"
tag_matching = "**"
}
}
Now let’s configure them in tfvars:
docker_upstream_cached_registries = {
"dockerhub" = {
provider = "docker-hub"
endpoint_url = "https://hub.docker.com"
description = "Public Docker hub"
storage_quota = 2048
}
"quay.io" = {
endpoint_url = "https://quay.io"
description = "Public Quay.io"
storage_quota = 100
}
"gcr.io" = {
endpoint_url = "https://gcr.io"
description = "Public Google repository"
storage_quota = 10
}
"ghcr.io" = {
endpoint_url = "https://ghcr.io"
description = "Public GitHub repository"
storage_quota = 100
}
}
Replicate some public repository images
Caching is very nice, but we can image some very sensible image we want to always have locally, even if the upstream registry is down. For this we can use replication. It’s a powerful feature of harbor permitting to select images based on criterias to replicate them locally.
Let’s configure a new project with a 1y retention policy and replicate all images based on some patterns in our local repository.
variable "public_replicated_repository" {
type = map(any)
default = {}
}
variable "public_replication" {
type = list(map(any))
description = "local replications"
default = []
}
resource "harbor_project" "local-replicated" {
for_each = var.public_replicated_repository
name = "repl-${each.key}"
public = false
storage_quota = try(each.value.storage_quota, 50)
}
resource "harbor_retention_policy" "local-replicated" {
for_each = var.public_replicated_repository
scope = harbor_project.local-replicated[each.key].id
schedule = "Daily"
rule {
n_days_since_last_pull = 365
repo_matching = "**"
tag_matching = "**"
}
rule {
most_recently_pulled = 10
repo_matching = "**"
tag_matching = "**"
}
rule {
n_days_since_last_push = 30
repo_matching = "**"
tag_matching = "**"
}
}
resource "harbor_replication" "local-replicated" {
for_each = {
for index, replication in var.public_replication :
"${replication.source_registry}->${replication.dest_registry} (${replication.image_name})" => replication
}
name = each.key
action = "pull"
registry_id = harbor_project.public-cache[each.value.source_registry].registry_id
schedule = "0 0/15 * * * *"
dest_namespace = "repl-${each.value.dest_registry}"
dest_namespace_replace = -1
filters {
name = each.value.image_name
}
filters {
tag = try(each.value.image_tag_regex, "**")
}
}
Now we have the global mechanism to replicate images, let’s configure some replication in tfvars:
public_replication = [
{
source_registry = "dockerhub"
image_name = "library/traefik"
image_tag_regex = "v2.{10}.{?,??}"
dest_registry = "kubernetes-core"
},
{
source_registry = "dockerhub"
image_name = "fluent/fluent-bit"
image_tag_regex = "2.1.{?,??}"
dest_registry = "kubernetes-core"
}
}
It will replicate fluentbit and traefik from the Docker hub to our local registry, only for 2.10.x versions of traefik and 2.1.x versions of fluentbit.
Bonus point
Cache an internal artifactory to make harbor a global distributed cache
I add here a bonus point, as we are using Artifactory as a global push registry for now at work. Idea is to give team some time to migrate to use our global caching registry instead of the single datacenter Artifactory, and at a point make them migrate fully to Harbor.
Idea is to discover all registered Artifactory Docker repositories and create cached Docker repositories in Harbor
First, let’s configure artifactory provider connection:
terraform {
backend "s3" {}
required_providers {
artifactory = {
source = "jfrog/artifactory"
version = "8.4.0"
}
}
}
// Artifactory connection for caching
variable "artifactory_url" {
type = string
default = ""
}
variable "artifactory_registry_domain" {
type = string
}
data "vault_generic_secret" "artifactory_access_token" {
path = local.path_artifactory_access_token
}
provider "artifactory" {
check_license = false
url = var.artifactory_url
access_token = data.vault_generic_secret.artifactory_access_token.data["admin_access_token"]
}
Then create a global read user on Artifactory and discover all repositories:
data "http" "artifactory_packages" {
url = "https://${var.artifactory_registry_domain}/ui/api/v1/ui/repodata?packageSearch=true"
# Optional request headers
request_headers = {
Accept = "application/json"
Authorization = "Basic ${local.artifactory_basic}"
}
}
resource "artifactory_user" "harbor-ro" {
name = local.artifactory_user
password = data.vault_generic_secret.artifactory_access_token.data["harbor_ro_password"]
email = "noreply@veepee.com"
admin = false
profile_updatable = false
disable_ui_access = false
internal_password_disabled = false
groups = ["readers"]
}
locals {
# In another product
path_artifactory_access_token = "secret/<path>/artifactory"
# but it's not so easy
artifactory_user = "harbor-ro"
artifactory_basic = base64encode("${local.artifactory_user}:${data.vault_generic_secret.artifactory_access_token.data.harbor_ro_password}")
# some magic to filter repository list from response
artifactory_repositories_to_replicate = [for v in jsondecode(data.http.artifactory_packages.response_body).repoTypesList : v.repoKey if lookup(v, "repoType") == "Docker" && lookup(v, "isLocal")]
}
On previous example we don’t use official artifactory API URL for repositories because, for unknown reason we don’t have all repositories, whereas cheating using the URL used by the UI it works fine.
Now let’s configure harbor with a cleanup policy to create all those new cached repositories.
// Now configure all registries from artifactory
resource "harbor_registry" "artifactory-docker" {
for_each = {
for index, replication in local.artifactory_repositories_to_replicate :
"${replication}" => replication
}
provider_name = "docker-registry"
name = each.key
endpoint_url = "https://${each.key}.${var.artifactory_registry_domain}"
description = "${each.key} repository from artifactory"
access_id = artifactory_user.harbor-ro.name
access_secret = data.vault_generic_secret.artifactory_access_token.data["harbor_ro_password"]
}
// and the caches
resource "harbor_project" "artifactory-cache" {
for_each = {
for index, replication in local.artifactory_repositories_to_replicate :
"${replication}" => replication
}
name = "cache-${each.key}"
public = false
storage_quota = try(each.value.storage_quota, 50)
registry_id = harbor_registry.artifactory-docker[each.key].registry_id
}
// artifactory cache keeps images pulled in the last 30 days or the 5 most recent images
resource "harbor_retention_policy" "artifactory-cache" {
for_each = {
for index, replication in local.artifactory_repositories_to_replicate :
"${replication}" => replication
}
scope = harbor_project.artifactory-cache[each.key].id
schedule = "Daily"
rule {
n_days_since_last_pull = 30
repo_matching = "**"
tag_matching = "**"
}
rule {
most_recently_pulled = 5
repo_matching = "**"
tag_matching = "**"
}
}
Conclusion
This project was very interesting and API based configuration is very powerful. We achieved here to create a multi datacenter replicated repository, accessible with a global URL through a GSLB, adding some caching of external repositories but also having a path permitting people to migrate smoothly to our new registry.
One of the next step is to contribute on official chart to propose Horizontal Pod Autoscaling like we did in order to reduce our patching.
I hope you enjoyed this article :) !